技术文档收录
ASCII
Tcpdump
Linux
WireGuard 一键安装脚本 | 秋水逸冰
SSH Config 那些你所知道和不知道的事 | Deepzz's Blog
Linux 让终端走代理的几种方法
ubuntu 20.04 server 版设置静态 IP 地址 - 链滴
Linux 挂载 Windows 共享磁盘的方法 - 技术学堂
将 SMB/CIFS 网络硬盘永久的挂载到 Ubuntu 上 - 简书
linux 获取当前脚本的绝对路径 | aimuke
[Linux] Linux 使用 / dev/urandom 生成随机数 - piaohua's blog
Linux 生成随机数的多种方法 | Just Do It
Linux 的 Centos7 版本下忘记 root 或者普通用户密码怎么办?
Git 强制拉取覆盖本地
SSH 安全加固指南 - FreeBuf 网络安全行业门户
Linux 系统安全强化指南 - FreeBuf 网络安全行业门户
Linux 入侵排查 - FreeBuf 网络安全行业门户
sshd_config 配置详解 - 简书
SSH 权限详解 - SegmentFault 思否
CentOS 安装 node.js 环境 - SegmentFault 思否
如何在 CentOS 7 上安装 Node.js 和 npm | myfreax
几款 ping tcping 工具总结
OpenVpn 搭建教程 | Jesse's home
openvpn 一键安装脚本 - 那片云
OpenVPN 解决 每小时断线一次 - 爱开源
OpenVPN 路由设置 – 凤曦的小窝
OpenVPN 设置非全局代理 - 镜子的记录簿
TinyProxy 使用帮助 - 简书
Ubuntu 下使用 TinyProxy 搭建代理 HTTP 服务器_Linux_运维开发网_运维开发技术经验分享
Linux 软件包管理工具 Snap 常用命令 - 简书
linux systemd 参数详解
Systemd 入门教程:命令篇 - 阮一峰的网络日志
记一次 Linux 木马清除过程
rtty:在任何地方通过 Web 访问您的终端
02 . Ansible 高级用法 (运维开发篇)
终于搞懂了服务器为啥产生大量的 TIME_WAIT!
巧妙的 Linux 命令,再来 6 个!
77% 的 Linux 运维都不懂的内核问题,这篇全告诉你了
运维工程师必备:请收好 Linux 网络命令集锦
一份阿里员工的 Java 问题排查工具单
肝了 15000 字性能调优系列专题(JVM、MySQL、Nginx and Tomcat),看不完先收
作业调度算法(FCFS,SJF,优先级调度,时间片轮转,多级反馈队列) | The Blog Of WaiterXiaoYY
看了这篇还不会 Linux 性能分析和优化,你来打我
2019 运维技能风向标
更安全的 rm 命令,保护重要数据
求你了,别再纠结线程池大小了!
重启大法好!线上常见问题排查手册
Docker
「Docker」 - 保存镜像 - 知乎
终于可以像使用 Docker 一样丝滑地使用 Containerd 了!
私有镜像仓库选型:Harbor VS Quay - 乐金明的博客 | Robin Blog
exec 与 entrypoint 使用脚本 | Mr.Cheng
Dockerfile 中的 CMD 与 ENTRYPOINT
使用 Docker 配置 MySQL 主从数据库 - 墨天轮
Alpine vs Distroless vs Busybox – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
再见,Docker!
Python
Pipenv:新一代Python项目环境与依赖管理工具 - 知乎
Python list 列表实现栈和队列
Python 各种排序 | Lesley's blog
Python 中使用 dateutil 模块解析时间 - SegmentFault 思否
一个小破网站,居然比 Python 官网还牛逼
Python 打包 exe 的王炸 - Nuitka
Window
批处理中分割字符串 | 网络进行时
Windows 批处理基础命令学习 - 简书
在Windows上设置WireGuard
Windows LTSC、LTSB、Server 安装 Windows Store 应用商店
中间件
Nginx 中的 Rewrite 的重定向配置与实践
RabbitMQ 的监控
RabbitMq 最全的性能调优笔记 - SegmentFault 思否
为什么不建议生产用 Redis 主从模式?
高性能消息中间件——NATS
详解:Nginx 反代实现 Kibana 登录认证功能
分布式系统关注点:仅需这一篇,吃透 “负载均衡” 妥妥的
仅需这一篇,妥妥的吃透” 负载均衡”
基于 nginx 实现上游服务器动态自动上下线——不需 reload
Nginx 学习书单整理
最常见的日志收集架构(ELK Stack)
分布式之 elk 日志架构的演进
CAT 3.0 开源发布,支持多语言客户端及多项性能提升
Kafka 如何做到 1 秒处理 1500 万条消息?
Grafana 与 Kibana
ELK 日志系统之通用应用程序日志接入方案
ELK 简易 Nginx 日志系统搭建: ElasticSearch+Kibana+Filebeat
记一次 Redis 连接池问题引发的 RST
把 Redis 当作队列来用,你好大的胆子……
Redis 最佳实践:业务层面和运维层面优化
Redis 为什么变慢了?常见延迟问题定位与分析
好饭不怕晚,扒一下 Redis 配置文件的底 Ku
rabbitmq 集群搭建以及万级并发下的性能调优
别再问我 Redis 内存满了该怎么办了
Nginx 状态监控及日志分析
数据库
SQLite全文检索
Mysql 查看用户连接数配置及每个 IP 的请求情况 - 墨天轮
防火墙-iptables
iptables 常用规则:屏蔽 IP 地址、禁用 ping、协议设置、NAT 与转发、负载平衡、自定义链
防火墙 iptables 企业防火墙之 iptables
Linux 防火墙 ufw 简介
在 Ubuntu 中用 UFW 配置防火墙
在 Ubuntu20.04 上怎样使用 UFW 配置防火墙 - 技术库存网
监控类
开箱即用的 Prometheus 告警规则集
prometheus☞搭建 | zyh
docker 部署 Prometheus 监控服务器及容器并发送告警 | chris'wang
PromQL 常用命令 | LRF 成长记
持续集成CI/CD
GitHub Actions 的应用场景 | 记录干杯
GithubActions · Mr.li's Blog
工具类
GitHub 中的开源网络广告杀手,十分钟快速提升网络性能
SSH-Auditor:一款 SHH 弱密码探测工具
别再找了,Github 热门开源富文本编辑器,最实用的都在这里了 - srcmini
我最喜欢的 CLI 工具
推荐几款 Redis 可视化工具
内网代理工具与检测方法研究
环境篇:数据同步工具 DataX
全能系统监控工具 dstat
常用 Web 安全扫描工具合集
给你一款利器!轻松生成 Nginx 配置文件
教程类
手把手教你打造高效的 Kubernetes 命令行终端
Keras 作者:给软件开发者的 33 条黄金法则
超详细的网络抓包神器 Tcpdump 使用指南
使用 fail2ban 和 FirewallD 黑名单保护你的系统
linux 下 mysql 数据库单向同步配置方法分享 (Mysql)
MySQL 快速删除大量数据(千万级别)的几种实践方案
GitHub 上的优质 Linux 开源项目,真滴牛逼!
WireGuard 教程:使用 Netmaker 来管理 WireGuard 的配置 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Tailscale 基础教程:Headscale 的部署方法和使用教程 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Nebula Graph 的 Ansible 实践
改进你的 Ansible 剧本的 4 行代码
Caddy 2 快速简单安装配置教程 – 高玩梁的博客
切换至 Caddy2 | 某不科学的博客
Caddy2 简明教程 - bleem
树莓派安装 OpenWrt 突破校园网限制 | Asttear's Blog
OpenVPN 路由设置 – 凤曦的小窝
个性化编译 LEDE 固件
盘点各种 Windows/Office 激活工具
[VirtualBox] 1、NAT 模式下端口映射
VirtualBox 虚拟机安装 openwrt 供本机使用
NUC 折腾笔记 - 安装 ESXi 7 - 苏洋博客
锐捷、赛尔认证 MentoHUST - Ubuntu 中文
How Do I Use A Client Certificate And Private Key From The IOS Keychain? | OpenVPN
比特记事簿: 笔记: 使用电信 TR069 内网架设 WireGuard 隧道异地组网
利用 GitHub API 获取最新 Releases 的版本号 | 这是只兔子
docsify - 生成文档网站简单使用教程 - SegmentFault 思否
【干货】Chrome 插件 (扩展) 开发全攻略 - 好记的博客
一看就会的 GitHub 骚操作,让你看上去像一位开源大佬
【计算机网络】了解内网、外网、宽带、带宽、流量、网速_墩墩分墩 - CSDN 博客
mac-ssh 配置 | Sail
如何科学管理你的密码
VirtualBox NAT 端口映射实现宿主机与虚拟机相互通信 | Shao Guoliang 的博客
CentOS7 配置网卡为静态 IP,如果你还学不会那真的没有办法了!
laisky-blog: 近期折腾 tailscale 的一些心得
使用 acme.sh 给 Nginx 安装 Let’ s Encrypt 提供的免费 SSL 证书 · Ruby China
acme 申请 Let’s Encrypt 泛域名 SSL 证书
从 nginx 迁移到 caddy
使用 Caddy 替代 Nginx,全站升级 https,配置更加简单 - Diamond-Blog
http.proxy - Caddy 中文文档
动手撸个 Caddy(二)| Caddy 命令行参数最全教程 | 飞雪无情的总结
Caddy | 学习笔记 - ijayer
Caddy 代理 SpringBoot Fatjar 应用上传静态资源
使用 graylog3.0 收集 open××× 日志进行审计_年轻人,少吐槽,多搬砖的技术博客_51CTO 博客
提高国内访问 github 速度的 9 种方法! - SegmentFault 思否
VM16 安装 macOS 全网最详细
2022 目前三种有效加速国内 Github
How to install MariaDB on Alpine Linux | LibreByte
局域网内电脑 - ipad 文件共享的三种方法 | 岚
多机共享键鼠软件横向测评 - 尚弟的小笔记
本文档发布于https://mrdoc.fun
-
+
首页
prometheus☞搭建 | zyh
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [zyh.cool](https://zyh.cool/posts/65820315/) prometheus 监控的构建,相比 zabbix 来说,还是要麻烦一些。 当然,如果你完全熟悉之后,配置文件化也更容易被其他系统所修改。 搞之前,先创建一个网络 docker network create promsnet grafana ------- 数据展示,部署在 proms 端 ``` mkdir -p /export/docker-data-grafana/{data,conf} chmod 777 /export/docker-data-grafana/data docker run --name grafana \ --network promsnet \ --mount 'type=bind,src=/export/docker-data-grafana/data,dst=/var/lib/grafana' \ --mount 'type=bind,src=/export/docker-data-grafana/conf,dst=/usr/share/grafana/conf' \ -p 3000:3000 -d grafana/grafana:7.3.5 ``` 默认账户 / 初始密码都是 admin 默认配置库是 sqlite 3 ### 配置 /export/docker-data-grafana/conf/default.ini ``` [server] domain = 域名 http_port = 端口 [database] type = sqlite3 host = 127.0.0.1:3306 name = grafana user = root password = [smtp] enabled = true host = smtp.feishu.cn:465 user = password = skip_verify = true from_address = from_name = GrafanaAdmin ``` alertmanager 告警管理 ----------------- 告警管理器,接收 proms 发来的告警,并加以处理后发出 ``` docker volume create alertmanager docker run --name alertmanager -d \ --network promsnet \ -p 9093:9093 \ --mount 'type=volume,src=alertmanager,dst=/etc/alertmanager' \ prom/alertmanager ``` ### 配置 alertmanager.yml ``` global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'wechat' receivers: - name: 'wechat' wechat_configs: - corp_id: '' to_user: '' agent_id: '' api_secret: '' send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] ``` 上面是微信的,你也可以 webhook 方式,来走其它方式,例如飞书 / 钉钉 ``` global: resolve_timeout: 5m route: group_by: ['instance'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook.prometheusalert' receivers: - name: 'web.hook.prometheusalert' webhook_configs: - url: '' # 这里填写 webhook 调用 inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] ``` 💁飞书 / 钉钉,可以用部署 [PrometheusAlert](https://gitee.com/feiyu563/PrometheusAlert) ### 告警分组、收敛、静默 分组的意思,就是将某一个组内同一时期的告警合并发送,例如根据实例来分组。 收敛的意思,就是告警 A 规则和告警 B 规则同时触发,但是告警 A 规则出现的时候,必然会触发告警 B,此时只发告警 A,例如 MYSQL 机器挂了,那么只需要发机器挂掉的告警,MYSQL 的告警就没必要发送了。 静默的意思,就是用户已知这个时间点会触发告警规则,但是无需触发,例如高压力定时任务引起磁盘 IO 告警,虽然会触发平均指标告警,但是在用户认定的安全范围内,因而无需触发。 * 分组 根据 label 进行分组,同组的预警尽量一次性发出 ``` route: group_by: ['alertname'] # 告警分组 group_wait: 10s # 分组等待时间,也就是说第一个告警等待同组内其它告警来临的时间 group_interval: 5m # 分组发送不同告警规则的静默周期,以及发送失败的静默周期 repeat_interval: 1h # 分组发送相同告警规则的静默周期,如果时间结束,告警状态未变,将再次发送. ``` * 收敛 举例说明:当主机挂了,此时只需要发送主机挂掉的预警,无需再发送因主机挂掉而产出的其它预警。 ``` inhibit_rules: - source_match: # 匹配最底层的那个告警规则,比如服务器挂了 severity: 'critical' target_match: # 匹配当 source_match 触发的时候,无需告警的规则。 severity: 'warn' equal: ['instance'] # 根据标签确定哪些匹配到 target_match 的需要忽略。例如,equal: instance 那么当 source_match 和 target_match 的 instance 值一样的时候,target_match 被忽略。 ``` 标签的 key ,可以是你在 proms.rule 中自定义,也可以是被监控端组件采集数据后发给 proms 的。 Prometheus 主程 ------------- ``` mkdir /export/docker-data-proms/{data,conf} -p chmod 777 /export/docker-data-proms/data ``` ### 配置 #### 主配置 /export/docker-data-proms/promethesu.yml ``` # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "/etc/prometheus/conf/rules/*.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. # - job_name: 'prometheus' # static_configs: # - targets: ['proms:9090'] # - job_name: "grafana" # static_configs: # - targets: ['grafana:3000'] - job_name: "auto_discovery_dns" relabel_configs: - source_labels: ["__address__"] # 获取原始标签 regex: "(.*):9100" # 匹配原始标签的值 replacement: "$1" # 提取 regex 中拿到的值 target_label: "instance" # 设定要修改的目标标签 action: replace # 将目标标签的值替换为 replacement 提取的值 - source_labels: ["__address__"] # 获取原始标签 regex: "(.*):10052" # 匹配原始标签的值 replacement: "$1" # 提取 regex 中拿到的值 target_label: "instance" # 设定要修改的目标标签 action: replace # 将目标标签的值替换为 replacement 提取的值 metric_relabel_configs: - source_labels: ["__name__"] # 获取原始标签 regex: "^go_.*|^process_.*" # 匹配标签值 action: drop # 删除,不让数据落盘 dns_sd_configs: # 通过 dns srv 记录自动发现 - names: ["_prometheus._tcp.zjk.pj"] ``` ##### 原始标签和目标标签 可以在下图位置【Status】-【Service Discovery】中看到详情 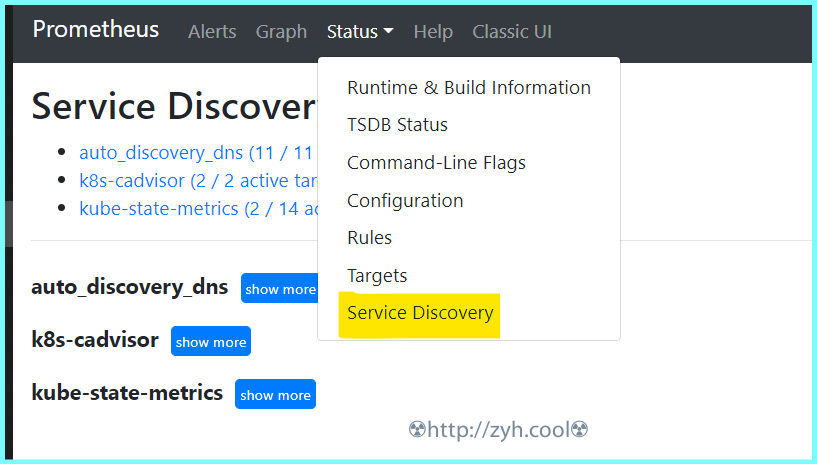 ##### 自动发现 dns srv 自动发现,需要一个内部的 dns 服务器,例如阿里云的云私有解析等。 如何添加 srv 记录,例如让 proms 发现节点服务 all.it.zjk.pj:9100 和 all.it.zjk.pj:10052 1. 添加私有域 zjk.pj 2. 添加 A 记录 all.it.zjk.pj -> 192.168.1.1 3. 添加 srv 记录 _prometheus._tcp.zjk.pj -> 10 10 9100 all.it.zjk.pj 4. 添加 srv 记录 _prometheus._tcp.zjk.pj -> 10 10 10052 all.it.zjk.pj 关于 A 记录就不说了,srv 记录里 `10 10 9100 all.it.zjk.pj`的意思是`优先级 权重 服务端口 服务器域名` 最终,你可以在 http://<prometheus_ip>:9090/classic/targets 看到自动发现的节点信息。 #### 定义需要告警的指标规则 将采集的数据指标通过 expr 进行运算,并通过 record 进行命名。 关于规则里的表达式语句的写法涉及到 PromQL,可以看一下文档。 [https://fuckcloudnative.io/prometheus/3-prometheus/basics.html](https://fuckcloudnative.io/prometheus/3-prometheus/basics.html) ##### 主机监控指标规则 /export/docker-data-proms/conf/rules/node-exporter-record-rules.yml ``` # node-exporter-record-rules.yml # 标签 job 关联主配置定义的任务 auto_discovery_dns,获取任务传递的数据,从而抽取信息定义 expr # 给 expr 表达式设置一个别名 record, 别名可以被其它 rules 调用 groups: - name: node_exporter-record rules: - expr: up{job=~"auto_discovery_dns"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:up labels: desc: "节点是否在线, 在线1,不在线0" unit: " " job: "auto_discovery_dns" - expr: time() - node_boot_time_seconds{}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:node_uptime labels: desc: "节点的运行时间" unit: "s" job: "auto_discovery_dns" ############################################################################################## # cpu # - expr: (1 - avg by (environment,instance) (irate(node_cpu_seconds_total{job="auto_discovery_dns",mode="idle"}[5m]))) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:cpu:total:percent labels: desc: "节点的cpu总消耗百分比" unit: "%" job: "auto_discovery_dns" - expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="auto_discovery_dns",mode="idle"}[5m]))) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:cpu:idle:percent labels: desc: "节点的cpu idle百分比" unit: "%" job: "auto_discovery_dns" - expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="auto_discovery_dns",mode="iowait"}[5m]))) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:cpu:iowait:percent labels: desc: "节点的cpu iowait百分比" unit: "%" job: "auto_discovery_dns" - expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="auto_discovery_dns",mode="system"}[5m]))) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:cpu:system:percent labels: desc: "节点的cpu system百分比" unit: "%" job: "auto_discovery_dns" - expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="auto_discovery_dns",mode="user"}[5m]))) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:cpu:user:percent labels: desc: "节点的cpu user百分比" unit: "%" job: "auto_discovery_dns" - expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="auto_discovery_dns",mode=~"softirq|nice|irq|steal"}[5m]))) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:cpu:other:percent labels: desc: "节点的cpu 其他的百分比" unit: "%" job: "auto_discovery_dns" ############################################################################################## # memory # - expr: node_memory_MemTotal_bytes{job="auto_discovery_dns"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:memory:total labels: desc: "节点的内存总量" unit: byte job: "auto_discovery_dns" - expr: node_memory_MemFree_bytes{job="auto_discovery_dns"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:memory:free labels: desc: "节点的剩余内存量" unit: byte job: "auto_discovery_dns" - expr: node_memory_MemTotal_bytes{job="auto_discovery_dns"} - node_memory_MemFree_bytes{job="auto_discovery_dns"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:memory:used labels: desc: "节点的已使用内存量" unit: byte job: "auto_discovery_dns" - expr: node_memory_MemTotal_bytes{job="auto_discovery_dns"} - node_memory_MemAvailable_bytes{job="auto_discovery_dns"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:memory:actualused labels: desc: "节点用户实际使用的内存量" unit: byte job: "auto_discovery_dns" - expr: (1-(node_memory_MemAvailable_bytes{job="auto_discovery_dns"} / (node_memory_MemTotal_bytes{job="auto_discovery_dns"})))* 100* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:memory:used:percent labels: desc: "节点的内存使用百分比" unit: "%" job: "auto_discovery_dns" - expr: ((node_memory_MemAvailable_bytes{job="auto_discovery_dns"} / (node_memory_MemTotal_bytes{job="auto_discovery_dns"})))* 100* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:memory:free:percent labels: desc: "节点的内存剩余百分比" unit: "%" job: "auto_discovery_dns" ############################################################################################## # load # - expr: sum by (instance) (node_load1{job="auto_discovery_dns"})* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:load:load1 labels: desc: "系统1分钟负载" unit: " " job: "auto_discovery_dns" - expr: sum by (instance) (node_load5{job="auto_discovery_dns"})* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:load:load5 labels: desc: "系统5分钟负载" unit: " " job: "auto_discovery_dns" - expr: sum by (instance) (node_load15{job="auto_discovery_dns"})* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:load:load15 labels: desc: "系统15分钟负载" unit: " " job: "auto_discovery_dns" ############################################################################################## # disk # - expr: node_filesystem_size_bytes{job="auto_discovery_dns" ,fstype=~"ext4|xfs"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:usage:total labels: desc: "节点的磁盘总量" unit: byte job: "auto_discovery_dns" - expr: node_filesystem_avail_bytes{job="auto_discovery_dns",fstype=~"ext4|xfs"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:usage:free labels: desc: "节点的磁盘剩余空间" unit: byte job: "auto_discovery_dns" - expr: node_filesystem_size_bytes{job="auto_discovery_dns",fstype=~"ext4|xfs"} - node_filesystem_avail_bytes{job="auto_discovery_dns",fstype=~"ext4|xfs"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:usage:used labels: desc: "节点的磁盘使用的空间" unit: byte job: "auto_discovery_dns" - expr: (1 - node_filesystem_avail_bytes{job="auto_discovery_dns",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{job="auto_discovery_dns",fstype=~"ext4|xfs"}) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:used:percent labels: desc: "节点的磁盘的使用百分比" unit: "%" job: "auto_discovery_dns" - expr: irate(node_disk_reads_completed_total{job="auto_discovery_dns"}[1m])* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:read:count:rate labels: desc: "节点的磁盘读取速率" unit: "次/秒" job: "auto_discovery_dns" - expr: irate(node_disk_writes_completed_total{job="auto_discovery_dns"}[1m])* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:write:count:rate labels: desc: "节点的磁盘写入速率" unit: "次/秒" job: "auto_discovery_dns" - expr: (irate(node_disk_written_bytes_total{job="auto_discovery_dns"}[1m]))/1024/1024* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:read:mb:rate labels: desc: "节点的设备读取MB速率" unit: "MB/s" job: "auto_discovery_dns" - expr: (irate(node_disk_read_bytes_total{job="auto_discovery_dns"}[1m]))/1024/1024* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:disk:write:mb:rate labels: desc: "节点的设备写入MB速率" unit: "MB/s" job: "auto_discovery_dns" ############################################################################################## # filesystem # - expr: (1 -node_filesystem_files_free{job="auto_discovery_dns",fstype=~"ext4|xfs"} / node_filesystem_files{job="auto_discovery_dns",fstype=~"ext4|xfs"}) * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:filesystem:used:percent labels: desc: "节点的inode的剩余可用的百分比" unit: "%" job: "auto_discovery_dns" ############################################################################################# # filefd # - expr: node_filefd_allocated{job="auto_discovery_dns"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:filefd_allocated:count labels: desc: "节点的文件描述符打开个数" unit: "%" job: "auto_discovery_dns" - expr: node_filefd_allocated{job="auto_discovery_dns"}/node_filefd_maximum{job="auto_discovery_dns"} * 100 * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:filefd_allocated:percent labels: desc: "节点的文件描述符打开百分比" unit: "%" job: "auto_discovery_dns" ############################################################################################# # network # - expr: avg by (environment,instance,device) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:netin:bit:rate labels: desc: "节点网卡eth0每秒接收的比特数" unit: "bit/s" job: "auto_discovery_dns" - expr: avg by (environment,instance,device) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:netout:bit:rate labels: desc: "节点网卡eth0每秒发送的比特数" unit: "bit/s" job: "auto_discovery_dns" - expr: avg by (environment,instance,device) (irate(node_network_receive_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:netin:packet:rate labels: desc: "节点网卡每秒接收的数据包个数" unit: "个/秒" job: "auto_discovery_dns" - expr: avg by (environment,instance,device) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:netout:packet:rate labels: desc: "节点网卡发送的数据包个数" unit: "个/秒" job: "auto_discovery_dns" - expr: avg by (environment,instance,device) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:netin:error:rate labels: desc: "节点设备驱动器检测到的接收错误包的数量" unit: "个/秒" job: "auto_discovery_dns" - expr: avg by (environment,instance,device) (irate(node_network_transmit_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:netout:error:rate labels: desc: "节点设备驱动器检测到的发送错误包的数量" unit: "个/秒" job: "auto_discovery_dns" - expr: node_tcp_connection_states{job="auto_discovery_dns", state="established"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:tcp:established:count labels: desc: "节点当前established的个数" unit: "个" job: "auto_discovery_dns" - expr: node_tcp_connection_states{job="auto_discovery_dns", state="time_wait"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:tcp:timewait:count labels: desc: "节点timewait的连接数" unit: "个" job: "auto_discovery_dns" - expr: sum by (environment,instance) (node_tcp_connection_states{job="auto_discovery_dns"})* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:network:tcp:total:count labels: desc: "节点tcp连接总数" unit: "个" job: "auto_discovery_dns" ############################################################################################# # process # - expr: node_processes_state{state="Z"}* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:process:zoom:total:count labels: desc: "节点当前状态为zoom的个数" unit: "个" job: "auto_discovery_dns" ############################################################################################# # other # - expr: abs(node_timex_offset_seconds{job="auto_discovery_dns"})* on(instance) group_left(nodename) (node_uname_info) record: node_exporter:time:offset labels: desc: "节点的时间偏差" unit: "s" job: "auto_discovery_dns" ############################################################################################# # - expr: count by (instance) ( count by (instance,cpu) (node_cpu_seconds_total{ mode='system'}) ) * on(instance) group_left(nodename) (node_uname_info) record: node_exporter:cpu:count ``` ##### 容器监控指标规则 /export/docker-data-proms/conf/rules/dockersInfo-record-rules.yml ``` groups: - name: dockersInfo-record rules: - expr: count by (instance, name) (count_over_time(container_last_seen{job="auto_discovery_dns", name!="", container_label_restartcount!=""}[15m])) record: dockersInfo:container:restart labels: desc: "15m周期内容器发生重启的次数" unit: "" job: "auto_discovery_dns" ############################################################################################## # cpu # - expr: rate(container_cpu_usage_seconds_total{job="auto_discovery_dns", name!=''}[5m]) * 100 record: dockersInfo:container:cpu:total:percent labels: desc: "容器的cpu总消耗百分比" unit: "%" job: "auto_discovery_dns" - expr: rate(container_fs_io_time_seconds_total{job="auto_discovery_dns", name!=''}[5m]) * 100 record: dockersInfo:cpu:iowait:percent labels: desc: "容器的cpu iowait百分比" unit: "%" job: "auto_discovery_dns" ############################################################################################## # memory # - expr: container_spec_memory_limit_bytes{job="auto_discovery_dns", name!=''} record: dockersInfo:memory:total labels: desc: "容器的内存总量" unit: byte job: "auto_discovery_dns" - expr: container_memory_usage_bytes{job="auto_discovery_dns", name!=''} / container_spec_memory_limit_bytes{job="auto_discovery_dns", name!=''} * 100 record: dockersInfo:memory:used:percent labels: desc: "容器的内存使用百分比" unit: "%" job: "auto_discovery_dns" ``` #### 定义监控指标阈值规则 ##### 主机监控指标阈值 /export/docker-data-proms/conf/rules/node-exporter-alert-rules.yml ``` # node-exporter-alert-rules.yml # 定义告警规则 # 通过前一个 rules 文件拿到定义的 record 别名来编写 expr 判断式 # 这里定义的告警规则,在触发的时候,都会传递到 alertmanager,最后从传递的信息中抽取所需数据发送给目标人。 groups: - name: node-alert rules: - alert: node-down expr: node_exporter:up == 0 for: 1m labels: severity: critical annotations: summary: "instance: {{ $labels.instance }} 宕机了" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-cpu-high expr: node_exporter:cpu:total:percent > 80 for: 3m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} cpu 使用率高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-cpu-iowait-high expr: node_exporter:cpu:iowait:percent >= 12 for: 3m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} cpu iowait 使用率高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-load-load1-high expr: (node_exporter:load:load1) > (node_exporter:cpu:count) * 1.2 for: 3m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} load1 使用率高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-memory-high expr: node_exporter:memory:used:percent > 85 for: 3m labels: severity: info annotations: summary: "内存使用率高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-disk-high expr: node_exporter:disk:used:percent > 80 for: 3m labels: severity: info annotations: summary: "{{ $labels.device }}:{{ $labels.mountpoint }} 使用率高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-disk-read:count-high expr: node_exporter:disk:read:count:rate > 3000 for: 2m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} iops read 使用率高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-disk-write-count-high expr: node_exporter:disk:write:count:rate > 3000 for: 2m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} iops write 使用率高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-disk-read-mb-high expr: node_exporter:disk:read:mb:rate > 60 for: 2m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 读取字节数 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-disk-write-mb-high expr: node_exporter:disk:write:mb:rate > 60 for: 2m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 写入字节数 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-filefd-allocated-percent-high expr: node_exporter:filefd_allocated:percent > 80 for: 10m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 打开文件描述符 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-network-netin-error-rate-high expr: node_exporter:network:netin:error:rate > 4 for: 1m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 包进入的错误速率 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-network-netin-packet-rate-high expr: node_exporter:network:netin:packet:rate > 35000 for: 1m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 包进入速率 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-network-netout-packet-rate-high expr: node_exporter:network:netout:packet:rate > 35000 for: 1m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 包流出速率 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-network-tcp-total-count-high expr: node_exporter:network:tcp:total:count > 40000 for: 1m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} tcp连接数量 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-process-zoom-total-count-high expr: node_exporter:process:zoom:total:count > 10 for: 10m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 僵死进程数量 高于 {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: node-time-offset-high expr: node_exporter:time:offset > 0.03 for: 2m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} {{ $labels.desc }} {{ $value }}{{ $labels.unit }}" grafana: "http://jksgg.pengwin.com:3000/d/9CWBz0bik/node-exporter?orgId=1&var-instance={{ $labels.instance }} " console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" ``` ##### 容器监控指标阈值 /export/docker-data-proms/conf/rules/dockersInfo-alert-rules.yml ``` groups: - name: container-alert rules: - alert: container-restart-times-high expr: dockersInfo:container:restart > 5 for: 1m labels: severity: warn annotations: summary: "instance: {{ $labels.instance }} 下的 container: {{ $labels.name }} 15分钟内重启次数超过5次" grafana: "http://proms.pengwin.com:3000/d/Ss3q6hSZk/dockersinfo?orgId=1&var-node={{ $labels.instance }}" console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: container-cpu-usage-high expr: dockersInfo:container:cpu:total:percent > 90 for: 1m labels: severity: info annotations: summary: "instance: {{ $labels.instance }} 下的 container: {{ $labels.name }} cpu 使用率持续超过90%." grafana: "http://proms.pengwin.com:3000/d/Ss3q6hSZk/dockersinfo?orgId=1&var-node={{ $labels.instance }}" console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" - alert: container-cpu-iowait-high expr: dockersInfo:cpu:iowait:percent > 10 for: 1m labels: severity: warn annotations: summary: "instance: {{ $labels.instance }} 下的 container: {{ $labels.name }} cpu iowait 持续超过10%" grafana: "http://proms.pengwin.com:3000/d/Ss3q6hSZk/dockersinfo?orgId=1&var-node={{ $labels.instance }}" console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" id: "{{ $labels.instanceid }}" type: "aliyun_meta_ecs_info" # - alert: container-mem-usage-high # expr: dockersInfo:memory:used:percent > 80 # for: 1m # labels: # severity: warn # annotations: # summary: "instance: {{ $labels.instance }} 下的 container: {{ $labels.name }} 内存使用率超过80%" # grafana: "http://proms.pengwin.com:3000/d/Ss3q6hSZk/dockersinfo?orgId=1&var-node={{ $labels.instance }}" # console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing" # cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true" # id: "{{ $labels.instanceid }}" # type: "aliyun_meta_ecs_info" ``` ### 部署 #### docker 方式 ``` docker run -d \ --network promsnet \ -p 9090:9090 \ --name proms \ --mount 'type=bind,src=/export/docker-data-proms/prometheus.yml,dst=/etc/prometheus/prometheus.yml' \ --mount 'type=bind,src=/export/docker-data-proms/data,dst=/prometheus' \ --mount 'type=bind,src=/export/docker-data-proms/conf,dst=/etc/prometheus/conf' \ prom/prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/prometheus --storage.tsdb.retention=30d ``` #### 二进制方式 ``` wget https://github.com/prometheus/prometheus/releases/download/v2.20.0/prometheus-2.20.0.linux-amd64.tar.gz mkdir prometheus tar xf prometheus-2.20.0.linux-amd64.tar.gz --strip-components 1 -C prometheus rm -rf prometheus-2.20.0.linux-amd64.tar.gz cd prometheus && baseDir=`pwd` cp prometheus.yml{,.bak} #--- cat > /usr/lib/systemd/system/prometheus.service <<EOF [Unit] Description=prometheus server daemon [Service] Restart=on-failure ExecStart=${baseDir}/prometheus --config.file=${baseDir}/prometheus.yml [Install] WantedBy=multi-user.target EOF #--- systemctl daemon-reload systemctl start prometheus ``` ### 查看 被监控端状态:[http://xxx:9090/targets](http://xxx:9090/targets) 通过上述地址,你可以看到配置中 job_name 定义的被监控任务的端点状态 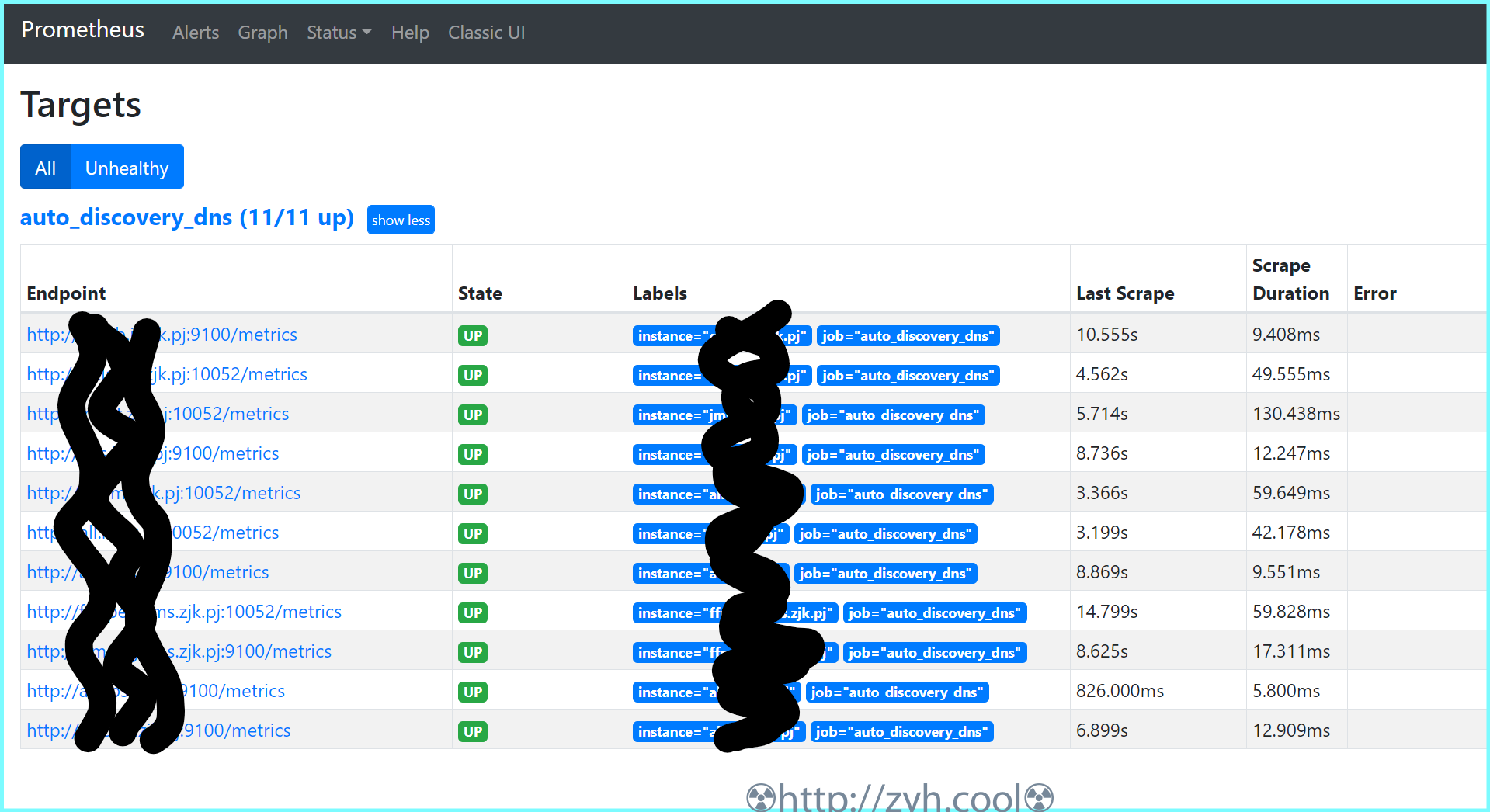 pushgateway (未验证) ----------------- push 模式下的网关 当前没有现成的推送模式的 node-exporter ``` # docker docker run -d --name=pushgateway -p 9091:9091 prom/pushgateway ``` ``` # 一个推送模式的采集脚本示例 # cat tcpestab.sh #!/bin/bash # 添加脚本到计划任务中,定时采集 # pushgateway ip pushgatewayIp= #获取主机名,常传输到Prometheus标签以主机名 instance_name=`hostname -f | cut -d'.' -f1` #判断主机名不能是localhost不然发送过的数据不知道是那个主机的 if [ $instance_name == "localhost" ];then echo "Hostname must not localhost" exit 1 fi #自定义key,在Prometheus即可使用key查询 label="count_estab_connections" #获取TCP estab 连接数 count_estab_connections=`netstat -an | grep -i 'established' | wc -l` #将数据发送到pushgateway固定格式 echo "$label $count_estab_connections" | curl --data-binary @- http://$pushgatewayIp:9091/metrics/job/pushgateway/instance/$instance_name ``` node-exporter 物理节点监控组件 ---------------------- 宿主数据采集端,部署在被监控主机的 9100 端口 ``` # 命令针对的是 cento7 cd /usr/local/ wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz mkdir node_exporter tar xf node_exporter-1.0.1.linux-amd64.tar.gz --strip-components 1 -C node_exporter mv node_exporter-1.0.1.linux-amd64.tar.gz src cd node_exporter && baseDir=`pwd` #--- cat > /usr/lib/systemd/system/node_exporter.service <<EOF [Unit] Description=node_exporter server daemon [Service] Restart=on-failure ExecStart=${baseDir}/node_exporter [Install] WantedBy=multi-user.target EOF #--- systemctl daemon-reload systemctl start node_exporter systemctl status node_exporter curl http://localhost:9100/metrics # 查看获取的监控数据 systemctl enable node_exporter ``` cadvisor 容器监控组件 --------------- 容器数据采集端,部署在被监控容器所在宿主的 10052 端口 ``` dockerRoot=`docker info | awk -F':' '/Docker Root Dir/{print $2}'|sed 's@^ *@@g'` echo $dockerRoot docker run \ --restart=always \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \ --volume=/sys:/sys:ro \ --volume=${dockerRoot}/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=10052:8080 \ --privileged=true \ --detach=true \ --name=cadvisor \ google/cadvisor:latest ``` 添加 grafana 数据源 : proms ---------------------- 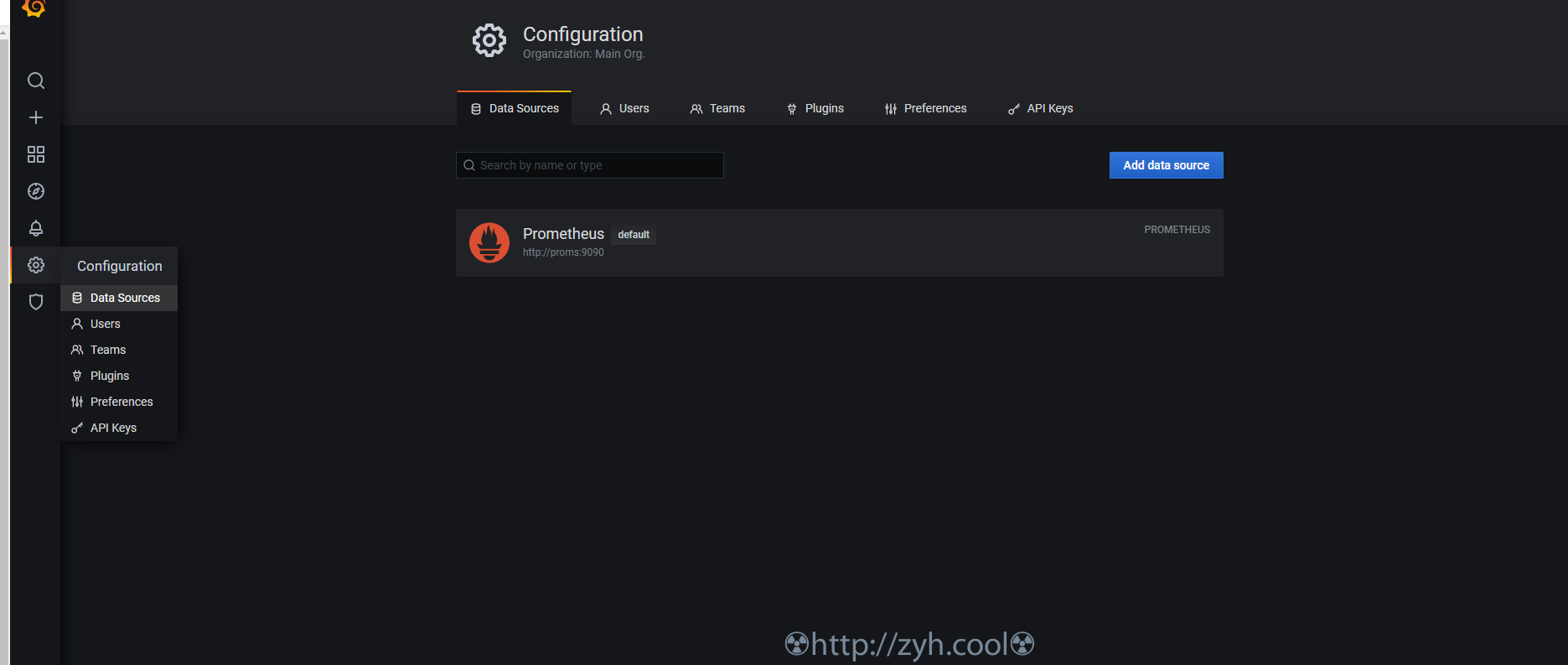 添加 grafana 监控模板 --------------- 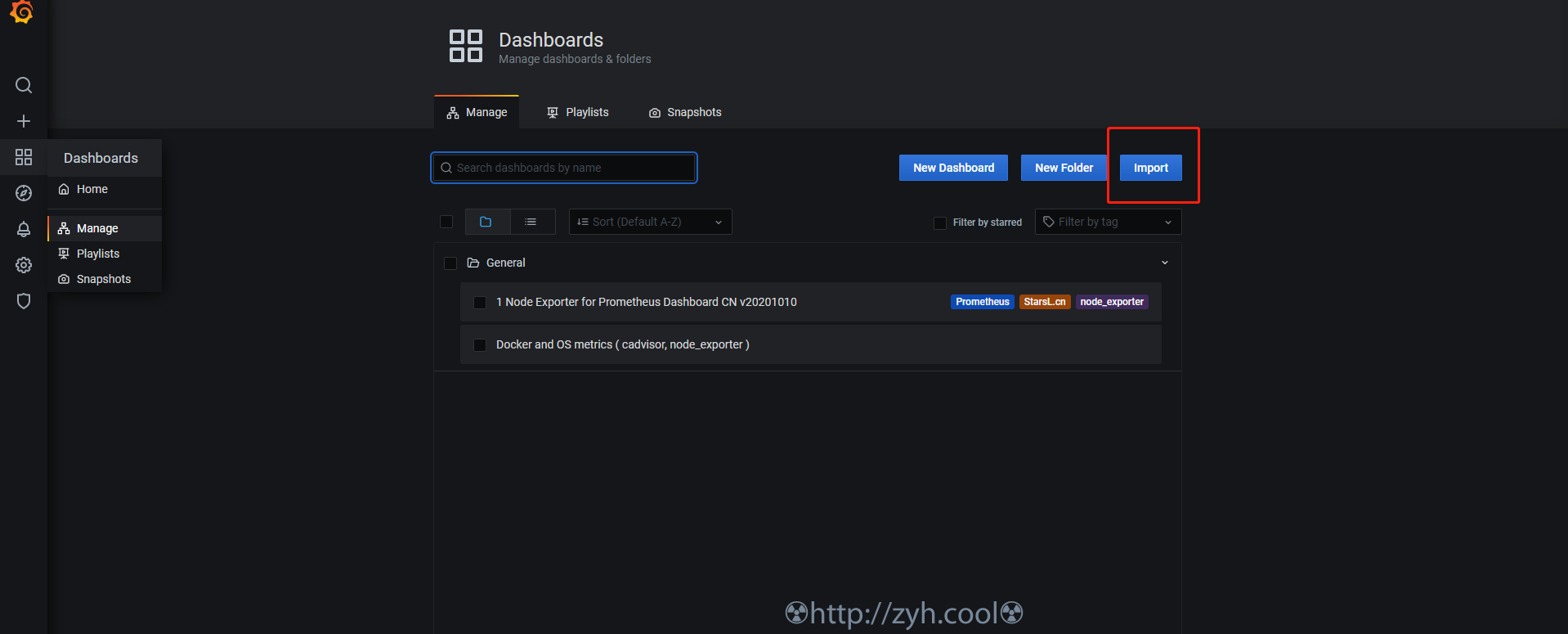 node 模板:[https://grafana.com/grafana/dashboards/8919](https://grafana.com/grafana/dashboards/8919) docker 模板:[https://grafana.com/grafana/dashboards/10566](https://grafana.com/grafana/dashboards/10566)
Jonny
2021年9月16日 12:23
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
【腾讯云】爆款2核2G4M云服务器一年45元,企业首购最高获赠300元京东卡
【腾讯云】爆款2核2G4M云服务器一年45元,企业首购最高获赠300元京东卡
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期